News: 2.0 is now in soft-launch. The environment is stable and a working version of the RL baseline is available, but not everything has been fully tuned and documented.
Neural MMO is a computationally accessible, open-source research platform that simulates populations of agents in virtual worlds. We challenge you to train a team of agents to complete tasks they have never seen before against opponents they have never seen before on maps they have never seen before. Our objective is to spur research on increasingly general and cognitively realistic environments.

 Neural MMO#
Neural MMO#
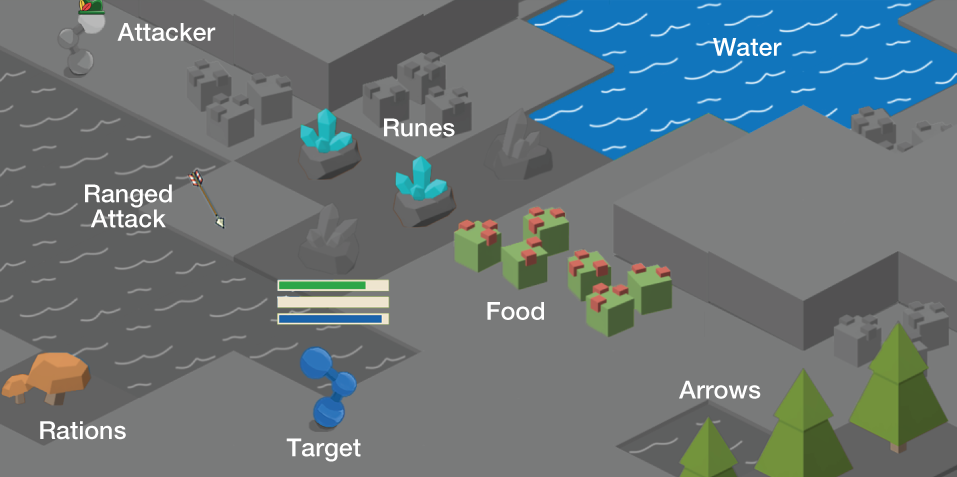
Your team of 8 Agents must collect food and water to survive. Each Agent has 8 individual professions to help them collect resources. Agents can level up their skills in each profession.
Resources can be used to create consumable items that restore food, water and heath as well as to create ammunition that increases damage in combat. Higher level resources create better consumables and ammunition. Agents can also trade items on a global market.
Agents may aquire armor to protect themselves in combat and weapons to increase their damage output. Agents can attack each other using one of three styles: Melee, Range, and Magic. The world is populated by NPCs that can be defeated to obtain items and increase power.
- Docker container including Neural MMO and GPU-accelerated baselines. Guarantees correct dependencies and environment setup. We recommended the following setup for local containerized development:
Install Docker Hub, VSCode, and the VSCode dev containers plugin.
Clone the competition branch of PufferTank on Linux/MacOS/WSL
VSCode: F1 -> “Remote-Containers: Open Folder in Container” -> Select PufferTank folder
git clone https://github.com/pufferai/puffertank --branch=competition
#WARNING: No pip package during soft launch. Use Docker or source. Official support for Ubuntu 20.04/22.04, WSL, and MacOS
# Quotes for mac compatibility.
pip install "nmmo"
# Clone baselines repository
git clone https://github.com/neuralmmo/baselines
Only recommended for developers of Neural MMO who can’t run PufferTank.
mkdir neural-mmo && cd neural-mmo
git clone https://github.com/neuralmmo/environment
git clone https://github.com/neuralmmo/baselines
cd environment && pip install -e .[all]
# If you want a local copy of the client.
# WSL users should run this part on Windows
# Download Cocos2d to open
git clone https://github.com/neuralmmo/client
Harvest resources with various uses
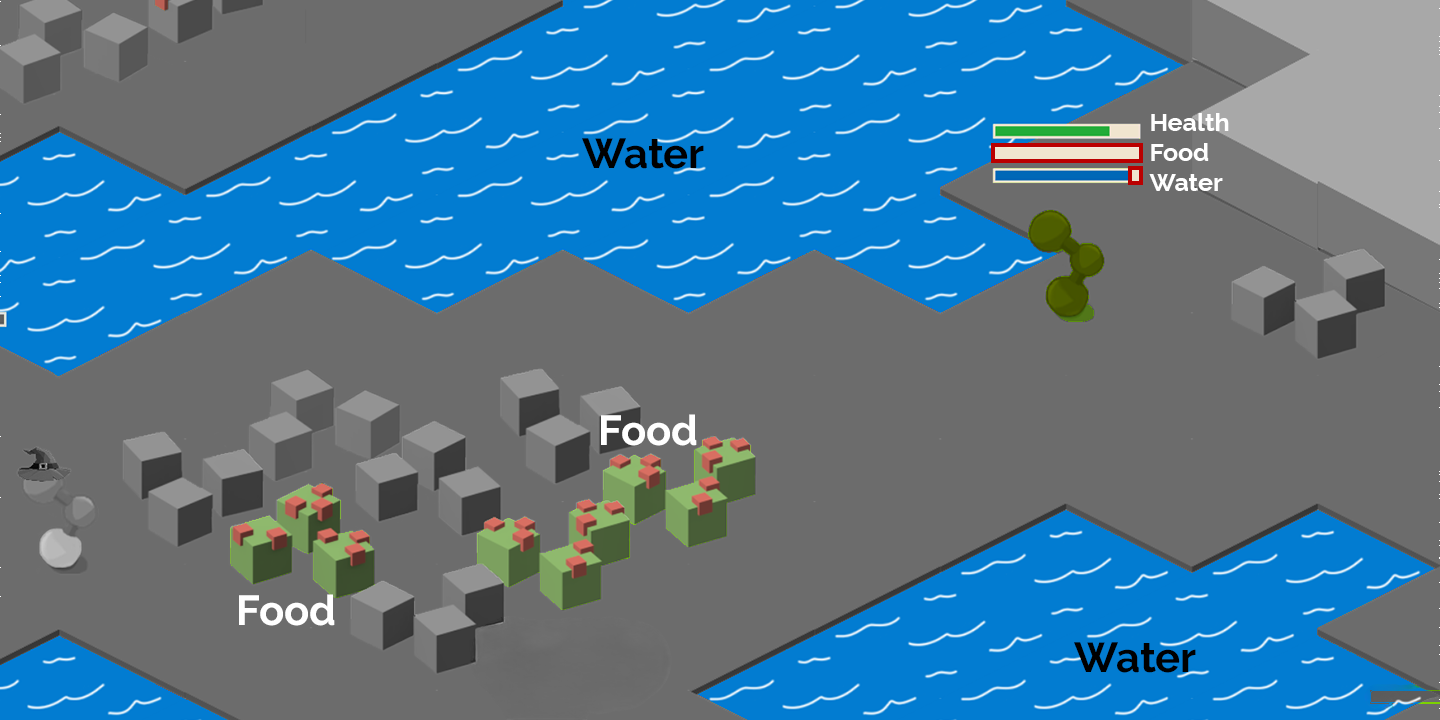
Forage for food and water to maintain your health
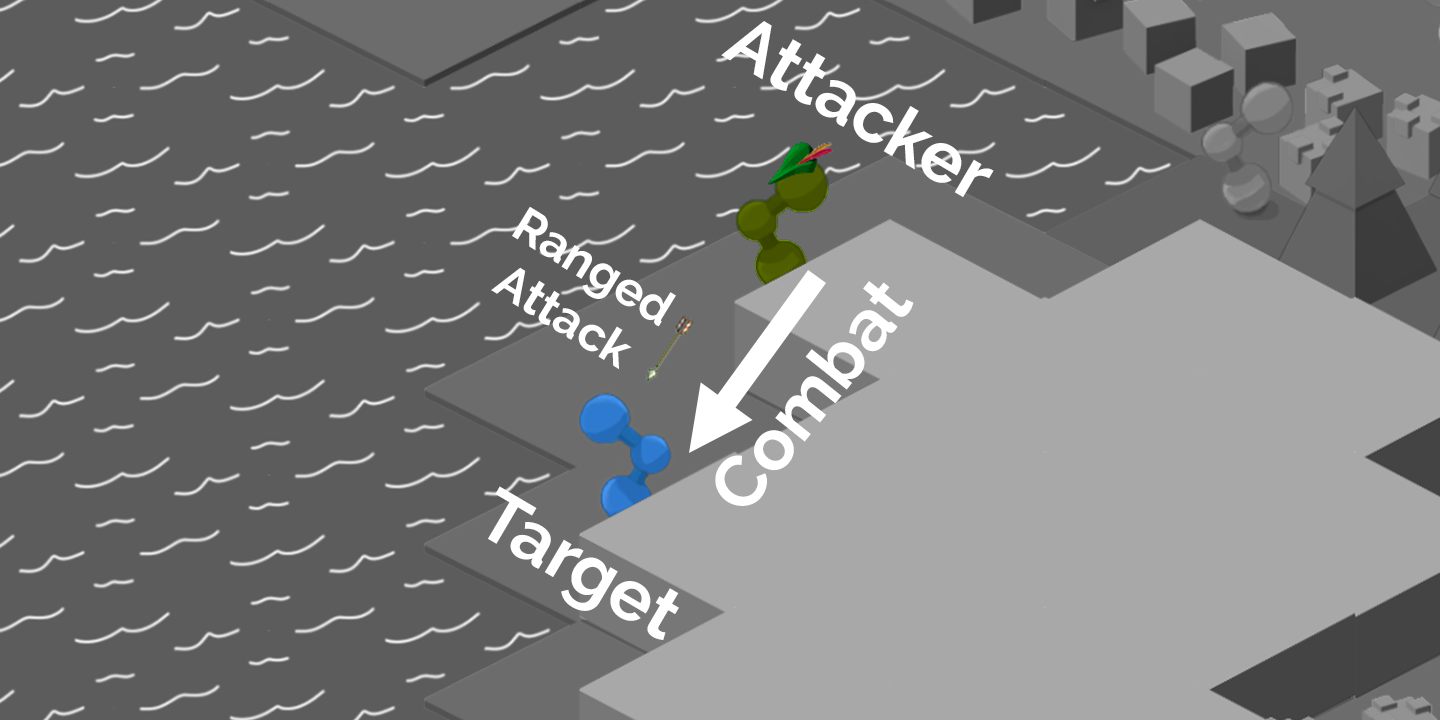
Fight other agents and NPCs with Melee, Range, and Magic
Interact with Non-Playable Characters of varying friendliness

Train combat and profession skills to access higher level items and equipment
Acquire consumables and and ammunition through professions

Increase offensive and defensive capabilities with weapons and armor
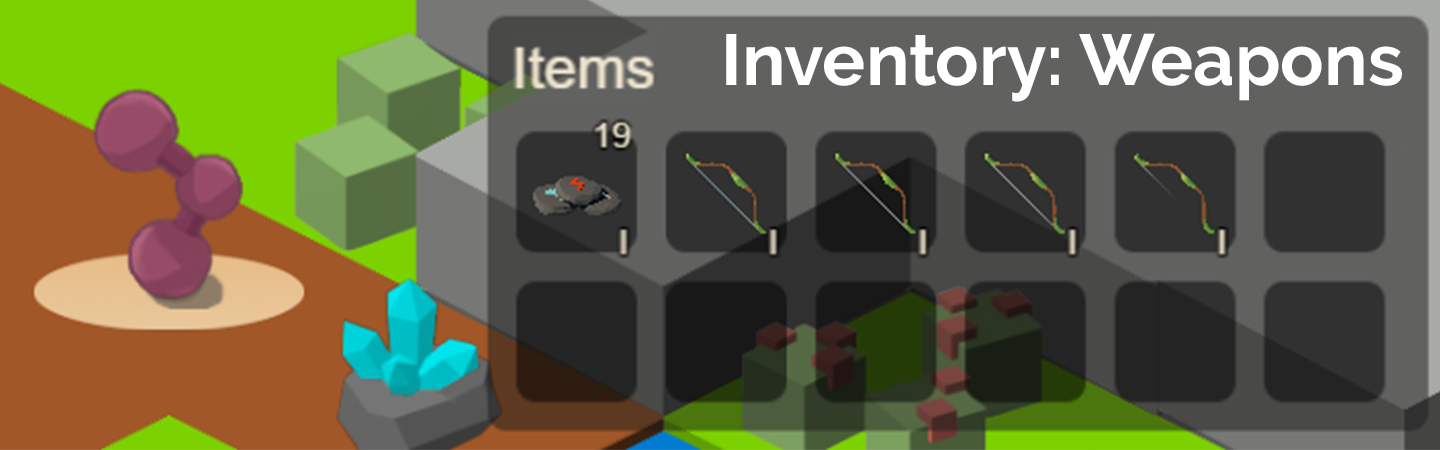
Trade items and equipment with other agents on a global market
Navigate procedurally generated maps

Contributors
Joseph Suarez: Creator and lead developer of Neural MMO.
- CarperAI team for NMMO 2.0:
David Bloomin: Rewrite of the engine for 2.0, port and development of the RL baseline
Kyoung Whan Choe: Rewrite of Neural MMO game code and logging for 2.0, contributions to the RL baseline and task system
Hao Xiang Li: Neural MMO 2.0 task system
Ryan Sullivan: Integration with Syllabus for the curriculum learning baseline
Nishaanth Kanna: Co-developer of the ELM curriculum baseline
Daniel Scott: Co-developer of the ELM curriculum baseline
Rose S. Shuman: Technical writing for this documentation site and for the competition
Herbie Bradley: Supervision of the curriculum generation baseline with OpenELM
Louis Castricato: Co-founder and team lead of Carper AI; supervisor of Carper AI development efforts.
- Parametrix.ai Team. Competition orchestrators and creators of the 2.0 web client.
Kirsty You: Product manager, Parametrix.ai
Yuhao Jiang: Machine learning researcher, Parametrix.ai
Qimai Li: Senior machine learning researcher, Paramerix.ai
Jiaxin Chen: Senior machine learning researcher. Co-organizer of 3rd and 4th Neural MMO Challenge
Xiaolong Zhu: Senior R&D Director, Paramerix.ai
Nick Jenkins: Layout for design for the competition poster. Adversary.design.
Sara Earle: Created 3D assets and 2D icons for items in NMMO 2.0. Hire her on UpWork if you like what you see here.
- Previous open source contributors, listed by time since latest contribution. Discord handle have been used for individuals who have not granted explicit permission to display their real names:
Thomas Cloarec: Developed the dynamic programming backend for scripted baseline agents
Jack Garbus: Major contributions to the logging framework, feedback on the documentation and tutorials
@tdimeola: Feedback on the documentation and tutorials
@cehinson: Mac build of the Unity3D client
Yilun Du: Assisted with experiments for 1.0 at OpenAI
BibTex Citation
@inproceedings{nmmo_neurips,
author = {Suarez, Joseph and Du, Yilun and Zhu, Clare and Mordatch, Igor and Isola, Phillip},
booktitle = {Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks},
editor = {J. Vanschoren and S. Yeung},
pages = {},
title = {The Neural MMO Platform for Massively Multiagent Research},
url = {https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/44f683a84163b3523afe57c2e008bc8c-Paper-round1.pdf},
volume = {1},
year = {2021}
}
2023 Competition#
Successfully complete the most tasks to win! At stake are $20,000 in prizes sponsored by Parametrix.ai. All submissions receive A100 compute credits for training sponsored by Stability.ai. The competition is currently planned for the start of July 2023.
Neural MMO (NMMO) has three tracks to compete and win. In all tracks, the objective is for your team of 8 agents to accomplish more tasks than 15 other opponent teams. There are 128 Agents in play at the start of each round, and your submission will be evaluated over thousands of rounds with increasingly difficult tasks. Lobbies are made by a matchmaking algorithm that selects 16 teams of similar skill level. For the RL and Curriculum tracks, all entrants receive up to 8 hours of free A100 compute time per submission to train.
Train teams of agents using RL to complete tasks. Customize the RL algorithm, model, and reward structure, but leverage a fixed baseline curriculum of tasks for training.
This is an opportunity for you RL enthusiasts to test your skills building agents that can survive and thrive in a massively multiagent environment full of potential adversaries. Your task is to implement a policy that defines how your 8 Agent team performs within a novel environment. At the outset of each game, your team will receive a randomly generated task. Complete the task to score a point. We will evaluate submissions against each other over thousands of games. Whoever scores the most points wins.
The RL track includes control over the RL algorithm, environment rewards signal, observation featurization, and the neural network architecture. The presentation and sampling of tasks are provided by the baseline and are treated as constants. All RL agent teams are trained on the same baseline task curriculum. While hybrid methods are allowed, with the new emphasis on tasks, it is unlikely that pure traditional scripting will be effective.
We release a baseline repository that includes a model adapted from NetEase’s winning submission to the NeurIPS 2022 competition, a fixed curriculum of procedurally generated tasks, a single-file CleanRL PPO implementation, PufferLib integration for simpler training, and WandB for logging and visualization. The baseline is designed to be easy to use and modify. We encourage you to use it as a starting point for your own submissions.
- To get started:
train.py contains the main training file. Modify hyperprameters and scale here.
cleanrl_ppo_lstm.py contains the CleanRL PPO implementation. Modify it to alter the training algorithm. This version includes PufferLib integration and asynchronous environment execution.
/model contains the network definition. This is an advanced architecture with a custom featurizer and multiple subnetworks dedicated to processing different types of information.
/feature_extractor preprocesses observations from the environment before they are passed to the network. It separately processes the map, inventory, and market observations.
# Run training. This is very memory intensive!
# We are working on a smaller config
# The --use_serial_vecenv flat puts envs on a
# local process and is useful for debugging
python train.py
# Evaluate a trained checkpoint
python -m tools.evaluate --model.checkpoint model_weights/achievements_4x10_new.200.pt
The Curriculum track is a great way for programmers to compete and participate, without the need for advanced knowledge of AI. In this track, you will design unique and useful curricula for training successful teams on tasks. A curriculum is a structured set of tasks presented to the RL algorithm intelligently to maximize learning. Design the task generator, task sampler, and reward using Python.
All submitted curricula will be applied to the same baseline RL policy to control a team of agents. Your objective is to create a curriculum of tasks that results in better, more robust learning such that agents are able to complete tasks not seen during training. You will receive performance metrics to see how effective the curriculum is and iterate your training curriculum. The reinforcement learning algorithm, observation featurization, and neural network architecture are provided by the baseline and remain constant across teams.
The baseline for this track includes a fixed curriculum of tasks and OpenELM integration. For researchers and advanced users, we encourage approaches leveraging ELM and provide a code generation model with the baselines.
By default, Neural MMO provides a reward signal of 1 every tick the agent is alive. Our goal is to provide a flexible, powerful high level API to define rewards - and simple enough for even a language model to program. For example, to reward teams for exploring the map
scenario = Scenario(config)
scenario.add_tasks(p.DistanceTraveled(dist=64))
env.change_task(scenario.tasks)
We define a list of tasks, one for each team - to collectively travel 64 tiles away from the starting position. Agents are gradually rewarded as they move away, with a total reward summed to 1 on completion.
- Glossary of key terms
GameState is a simplified read-only snapshot view of the environment.
Group is an immutable set of agents.
Predicate is a special, clipped case of Task.
Scenario is a utility class to help assign subjects to tasks.
Task is a mapping from GameState to a reward shared across its (subject: Group). We provide utilities that cover many use cases.
Get started by defining your own tasks by building from our provided set of operators.
task = t.OR(p.CountEvent(event='PLAYER_KILL',N=5),p.TickGE(num_tick=5))
task = task * 5
scenario.add_tasks(task)
# Rewarding the agent for increasing time isn't helpful for training
# Try improving this task!
Some possibilities include OR different tasks to count progress towards either, and MUL (overloaded operator “*””) to scale up rewards. It is possible to explicitly assign subjects and groups to tasks.
env.change_task([StayAlive(Group([agent])) for agent in agents])
More expressivity is possible from decorators @define_task and @define_predicate.
@t.define_task
def KillTask(gs: GameState,
subject: Group): # Annotated with Group to expose env variables
""" Reward 0.1 per player defeated, with a bonus for the 1st and 3rd kills."""
num_kills = len(subject.event.PLAYER_KILL)
score = num_kills * 0.1
if num_kills >= 1:
score += 1
# You can use other tasks in a definition!
if p.CountEvent(subject=subject, event='PLAYER_KILL',N=3)(gs) == 1.0:
score += 1
return score
# scenario also accepts fn(Group -> Task), and calls this for all desired
# Groups. The default behavior (passing in Task) is similar to the
# lambda definition below.
# Defined across agents instead of teams.
scenario.add_tasks(lambda agent: KillTask(subject=agent), groups='agents')
We return a score for an input GameState and the reward each tick is the change in score. Advanced usage can involve directly inheriting from the base Task class or subclasses.
# TaskOperator itself is a subclass of Task
class Repeat(TaskOperator):
def __init__(self, task: Task, subject: Group=None):
""" The reward each turn is the value of the operand."""
super().__init__(lambda n: n==1, task, subject=subject)
self._current_score = 0
def _evaluate(self, gs: GameState) -> float:
self._current_score += self._tasks[0](gs)
return self._current_score
def sample(self, config: Config, **kwargs):
return super().sample(config, Repeat, **kwargs)
Combine RL and curriculum approaches. Entrants provide their own compute to win via any way possible - just don’t hack our servers!
Deploy both RL and Curriculum approaches to create the ultimate 8 Agent team policy. All methods are open and no constraints on (self-provided) compute. Only restrictions are: no unauthorized modifications of the game or other submissions.
If you are here, you know how to get started. Use any of the above baselines or build your own from scratch. This is the only track that does not strictly require winners to open-source their code. However, we strongly encourage you to do so.
Platform#
The project was inspired by classic Massively Multiplayer Online Role-Playing Games (MMOs) - a genre defined by interaction with a large number of other players. It is a platform for creating intelligent agents parameterized by neural networks. Our goal is to support a broad base of multiagent research that would be impractical or impossible to conduct using other environments. Unlike other game genres typically used in research, MMOs simulate persistent worlds that support rich player interactions and a wider variety of progression strategies. These properties seem important to intelligence in the real world. The massively multiagent setting allow player teams to interact in interesting ways and use entirely different strategies.
from nmmo import Env
# Default environment - see API for config options
env = Env(config=None)
obs = env.reset()
while True:
actions = {} # Compute with your model
obs, rewards, dones, infos = env.step(actions)
Environments provide a standard PettingZoo API. Join our community Discord and post in #support for help (do not raise Github issues for support). See the cards at the top of this page for source code, baselines, latest publications, social media, and news!